正式进入Netty核心组件:Reactor线程模型
看完本文应该明白这些问题:
1.为什么channel的操作是线程安全的?
2.NioEventLoop都干了啥?
3.如何解决jdk nio的空轮询的bug?
主流程
在开始之前先贴张图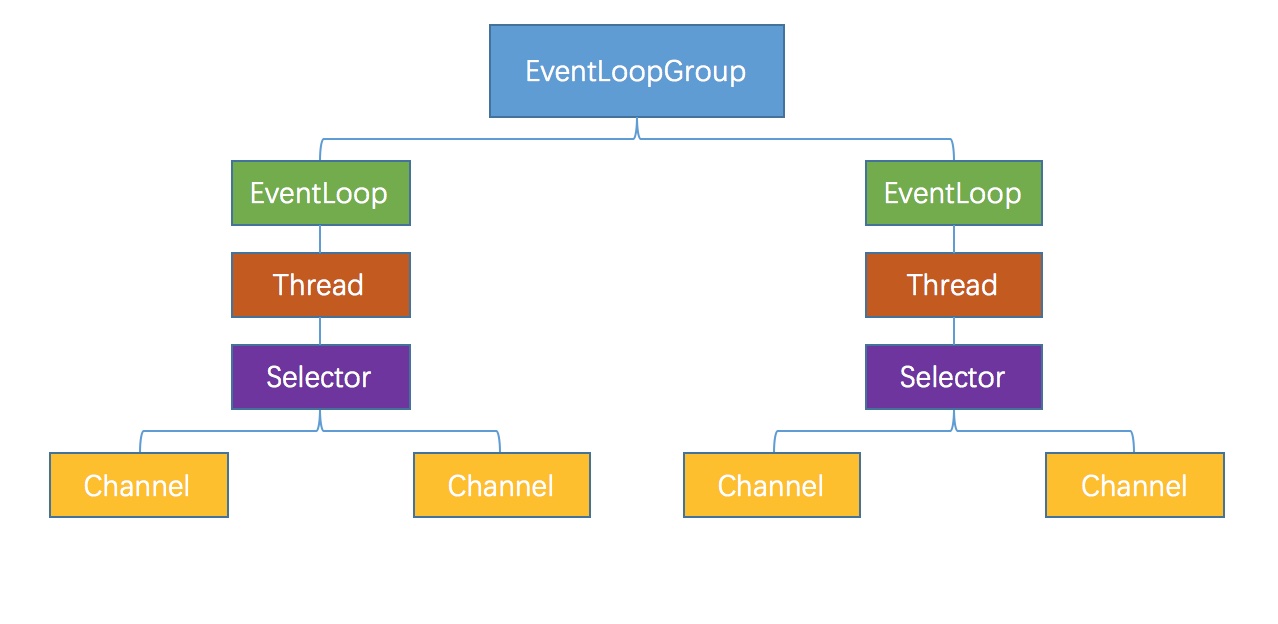
关于NioEventLoop,EventLoopGroup,Selector之间的关系如图1所示。
EventLoopGroup:NioEventLoop:Thread:Selector = 1:n:n:n
下面开始分析源码,还记得在上篇文章提到过,当服务端执行channel的注册时会执行这行代码channel.eventLoop().execute(xxx),而这行代码是NioEventLoop的入口。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//SingleThreadEventExecutor.class
public void execute(Runnable task) {
//...
boolean inEventLoop = inEventLoop();
if (inEventLoop) {
addTask(task);
} else {
startThread();
addTask(task);
if (isShutdown() && removeTask(task)) {
reject();
}
}
//...
}
这里先判断当前线程是否在EventLoop绑定的线程中(就是简单地进行Thread的比对),在服务端刚启动的时候代码会执行到else部分,我们看下startThread方法1
2
3
4
5
6
7
8//SingleThreadEventExecutor.class
private void startThread() {
if (STATE_UPDATER.get(this) == ST_NOT_STARTED) {
if (STATE_UPDATER.compareAndSet(this, ST_NOT_STARTED, ST_STARTED)) {
doStartThread();
}
}
}
这里也是Netty高性能之无锁化的一个体现,通过CAS保证即使在多线程竞争的时候也是线程安全。1
2
3
4
5
6
7
8
9
10
11
12
13//SingleThreadEventExecutor.class
private void doStartThread() {
//...
executor.execute(new Runnable() {
public void run() {
thread = Thread.currentThread();
SingleThreadEventExecutor.this.run();
success = true;
}
}
//...
}
这里可以看到线程(我们称为Reactor线程)是由run方法创建的,这里就是简单地将当前线程设置到SingleThreadEventExecutor中,值得注意的是这个当前线程指的是由线程池调度分配给执行run方法的线程。继续跟进run方法,这时候到了一个及其核心的地方。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
protected void run() {
for (;;) {
try {
switch (selectStrategy.calculateStrategy(selectNowSupplier, hasTasks())) {
case SelectStrategy.CONTINUE:
continue;
case SelectStrategy.SELECT:
select(wakenUp.getAndSet(false));
if (wakenUp.get()) {
selector.wakeup();
}
default:
// fallthrough
}
processSelectedKeys();
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
It’s time to show the 2rd picture.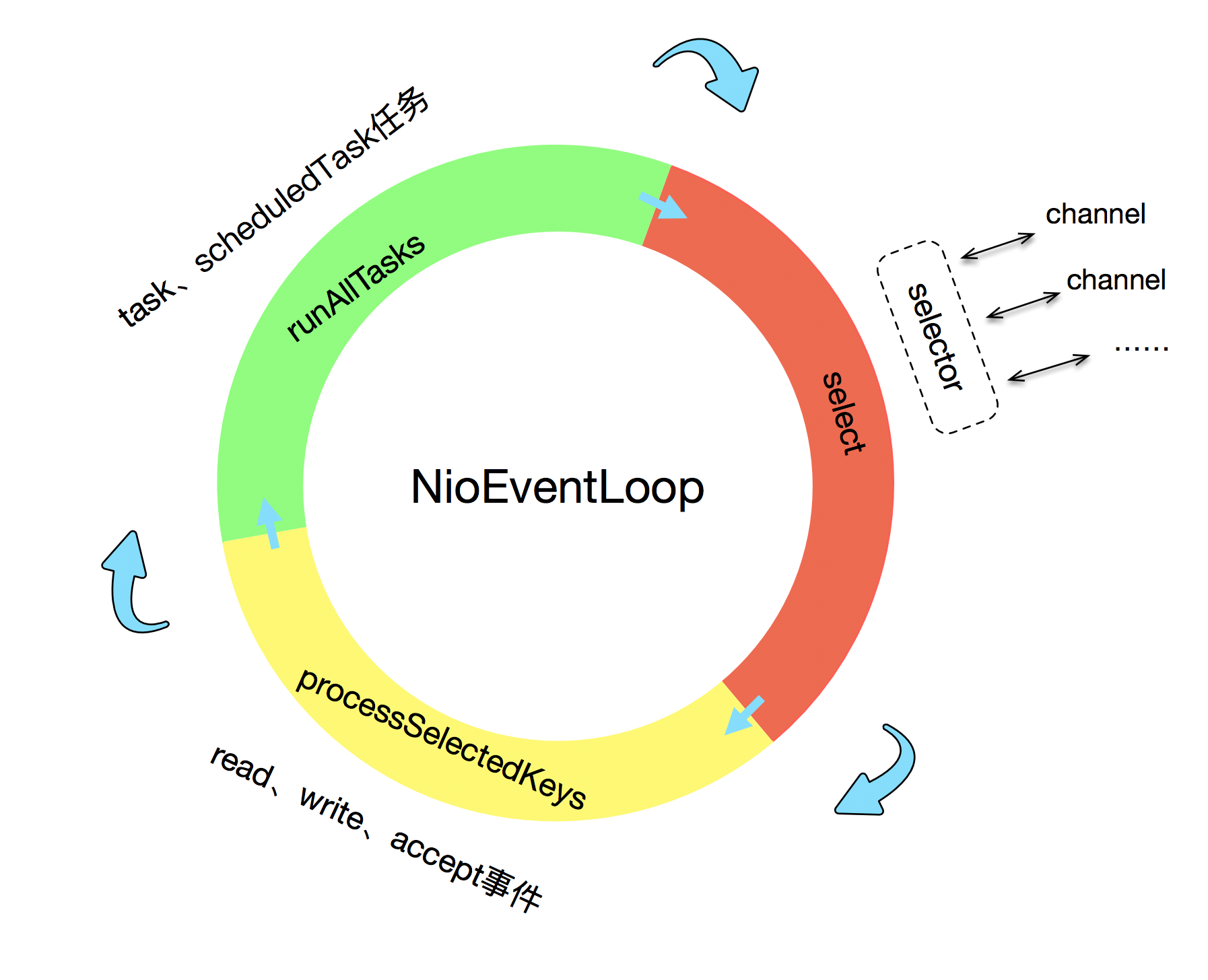
如图2所示,reactor线程一直在循环做三件事情
- select
- process selected keys
- run tasks
select
1 | select(wakenUp.getAndSet(false)); |
在进行select阻塞操作之前,先将wakenUp置为false。下面那段代码Netty源码注解写的天花乱坠,但我还是没理解。。。
这里留个问题吧,会有多个线程调用selector.select()操作吗?如果有这种场景就能理解了。
接着去看看select方法,这个方法很长,这里逐步去分析1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16private void select(boolean oldWakenUp) throws IOException {
Selector selector = this.selector;
try {
int selectCnt = 0;
long currentTimeNanos = System.nanoTime();
long selectDeadLineNanos = currentTimeNanos + delayNanos(currentTimeNanos);
for (;;) {
long timeoutMillis = (selectDeadLineNanos - currentTimeNanos + 500000L) / 1000000L;
if (timeoutMillis <= 0) {
if (selectCnt == 0) {
selector.selectNow();
selectCnt = 1;
}
break;
}
//...
这段代码,还没进入真正的select操作,首先记录了当前时间以及定时任务中到期时间最近任务的执行时间,接着代码进入了无限循环中,首先判断如果当前时间已经过了最近任务执行时间0.5ms以上,如果这时候还没执行过select or selectNow操作这时候执行一次立刻返回的selectNow操作,之后退出无限循环。1
2
3
4
5
6
7
8if (hasTasks() && wakenUp.compareAndSet(false, true)) {
selector.selectNow();
selectCnt = 1;
break;
}
int selectedKeys = selector.select(timeoutMillis);
selectCnt ++;
hasTask方法判断TaskQueue是否为空,如果不为空且CAS操作成功,那么立即执行一次selectNow并跳出无限循环。
如果不满足上述条件,代码来到了selector.select(timeout)方法。这是jdk的nio中的方法,带有超时时间,而且当其他线程调用selector.wakeUp时候会唤醒阻塞。执行完select操作后会对selectCnt+1。
自问自答
这里之前有些疑惑,为何要+0.5ms ?
后来想了下,如果没有这个0.5ms,那么select操作在没有定时任务的情况,可能会立刻停止阻塞甚至没有捕获任何事件。
再考虑另外一个极端情况,定时任务的delayNanos(currentTimeNanos)相当大,那么select操作岂不是要阻塞很久,那整个netty可能都玩不转了?
这里看了下源码,当select操作阻塞的时候是可以通过wakeup操作唤醒的,而添加任务的代码如下,这里是会唤醒select操作的1
2
3if (!addTaskWakesUp && wakesUpForTask(task)) {
wakeup(inEventLoop);
}
1 | if (selectedKeys != 0 || oldWakenUp || wakenUp.get() || hasTasks() || hasScheduledTasks()) { |
这里注解写的很清晰,当轮询到IO事件(select something)、被用户所唤醒、旧的wakenUp为true、任务队列有任务、定时任务要被执行,这时候要执行break操作,退出无限循环。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23long time = System.nanoTime();
if (time - TimeUnit.MILLISECONDS.toNanos(timeoutMillis) >= currentTimeNanos) {
// timeoutMillis elapsed without anything selected.
selectCnt = 1;
} else if (SELECTOR_AUTO_REBUILD_THRESHOLD > 0 &&
selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {
// The selector returned prematurely many times in a row.
// Rebuild the selector to work around the problem.
logger.warn(
"Selector.select() returned prematurely {} times in a row; rebuilding Selector {}.",
selectCnt, selector);
rebuildSelector();
selector = this.selector;
// Select again to populate selectedKeys.
selector.selectNow();
selectCnt = 1;
break;
}
currentTimeNanos = time;
} // end loop
这段代码就是专门为了解决jdk nio bug而写的。简单查了下这个bug,就是说当selector.select阻塞的时候,即使没有轮询到io事件也没有其他线程调用wakeup也会退出阻塞,将会无法退出循环导致cpu使用率一直是100%。
代码最开始就是检测上次的select操作是否阻塞了timeoutMills这么长,如果是那就能够说明没触发那个bug,所以将selectCnt置为1。相反阻塞时间不超过timeoutMills的次数达到了SELECTOR_AUTO_REBUILD_THRESHOLD次,那么这时候视为触发了bug,解决的方法很简单就是rebuild一个selector,将attachment(也就是channel),interestOps一起转移到新selector上。
简单总结下select操作
1)先去判断是否有快到期的定时任务,如果有那么selectNow并break
2)判断taskQueue中是否有任务,如果有那么selectNow()并break
3)执行selector.select(timeout),这里timeout表示定时任务的到期时间
4)最后通过巧妙的方式绕过了jdk的bug
processSelectedKeys
1 | private void processSelectedKeys() { |
这里Netty对selectedKeys进行了优化,原生的是一个hashSet,这里将其存到了数组中,方便访问与遍历。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33private void processSelectedKeysOptimized(SelectionKey[] selectedKeys) {
for (int i = 0;; i ++) {
final SelectionKey k = selectedKeys[i];
if (k == null) {
break;
}
selectedKeys[i] = null;
final Object a = k.attachment();
if (a instanceof AbstractNioChannel) {
processSelectedKey(k, (AbstractNioChannel) a);
} else {
("unchecked")
NioTask<SelectableChannel> task = (NioTask<SelectableChannel>) a;
processSelectedKey(k, task);
}
if (needsToSelectAgain) {
for (;;) {
i++;
if (selectedKeys[i] == null) {
break;
}
selectedKeys[i] = null;
}
selectAgain();
selectedKeys = this.selectedKeys.flip();
i = -1;
}
}
}
遍历selectedKeys,找到key和对应的channel,之后传入到processSelectedKey(k, (AbstractNioChannel) a);中处理,最后判断是否需要重新select,如果需要那么执行selectAgain()
先来看processSelectedKey1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
try {
int readyOps = k.readyOps();
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
int ops = k.interestOps();
ops &= ~SelectionKey.OP_CONNECT;
k.interestOps(ops);
unsafe.finishConnect();
}
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
ch.unsafe().forceFlush();
}
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
if (!ch.isOpen()) {
return;
}
}
}
}
可以看到这段代码就是根据轮询到的不同IO事件执行不同的操作。unsafe.read()已经在上篇文章中分析过了。
接着判断needsToSelectAgain,对于每个NioEventLoop而言,每隔256个channel从selector上移除的时候,就标记 needsToSelectAgain 为true,执行一次『洗牌』。这里就不进行具体的分析了。
runAllTasks
1 | protected boolean runAllTasks(long timeoutNanos) { |
(1)将到期的定时任务从一个优先队列(PriorityQueue)转移到MPSC(多生产者单消费者,Thread-Safe BlockingQueue)队列中
(2)从taskQueue中获取一个task
(3)计算本次任务循环的截止时间,因为需要留时间给select操作和process操作
(4)进入循环
(5)执行任务,如果被执行的任务到了64个(nanotime的获取是一个相对昂贵的操作,所以不是每次循环都去判断),此时去判断是否已经timeout,如果是的话那么直接break
(6)如果不符合上述要求,那么继续从taskQueue中拉取任务并执行
总结,Netty中的任务机制是其线程安全的一大保证。当非reactor线程执行一些并发操作时,都会把这次操作抽象为一个任务并将任务放到reactor线程的任务队列中等待reactor线程去执行。比如:channel的write操作、定时任务的优先队列任务的添加等操作都会被封装为一次普通的task。